

光学文字認識(OCR)は、数十年前から存在しています。では、実際にはどのような働きをするのでしょうか?画像を解析し、その中のテキストを読み取り、ユーザーが利用できる形式で結果を提供します。かつては、従来のOCRが主流でした。これらは文字を一つずつ機械的に読み取るものでした。特定の条件下では正確な場合もありましたが、条件が変わると不安定になることもありました。
今日、ClaudeのようなAIツールがその状況を一変させました。
本来、Claudeは単なるOCRツールではありません。これは視覚機能を備えたLLM(大規模言語モデル)であり、その点が非常に重要です。
Claudeは非常に強力で、スキャンされた請求書を読み取り、文脈を推測し、出力結果を生成することができます。この記事では、その仕組み、解決できる課題、そしてまだ課題が残る点について詳しく解説します。
ClaudeによるOCR
次のように考えてみましょう。Claudeは人間と同様の視覚機能を備えています。何かをスキャンすれば、すべての情報が目の前に現れます。同様に、ユーザーが画像やPDFをClaudeにアップロードすると、視覚的なコンテンツが言語モデル機能を通じて処理されたテキストに変換されます。これらの「視覚トークン」は、言語理解と同じ推論アーキテクチャを通過します。
実用上の意味:Claudeは単に文字を抽出するだけではありません。知識豊富な人間がそうするように文書を読み解き、各セクションの関連性を理解し、塗りつぶされたボックス内の数字がおそらく小計であることを認識し、見出しを構造的に重要な要素として解釈し、図のキャプションを2段落上に記述された表と結びつけます。
対応入力形式と制限
Claudeは、Claude.aiインターフェースおよびAnthropic APIの両方を通じて、画像(JPEG、PNG、GIF、WebP)およびPDFを受け付けます。2025年現在、Claude Sonnet 4は1回のリクエストで最大100万トークンのコンテキストをサポートしており、実用上、書籍全体、法的契約書類一式、あるいは研究論文のアーカイブを送信し、手動で分割することなく文書横断的な質問を行うことが可能です。Files API経由のファイルアップロードでは、最大500MBのドキュメントに対応しています。
特にスキャンされたPDFについては、Claudeは視覚ベースのOCR推論と表現するのが最も適切な処理を適用します:表の境界を検出し、列の配置を解釈し、画像内に埋め込まれたテキストを読み取り、レイアウトの認識とテキストの理解を組み合わせたハイブリッドな分析を再構築します。ネイティブのデジタルPDFは、視覚処理の基盤となるテキストレイヤーが存在するため、さらに高い精度で処理されます。
ClaudeのOCRの実用例
理論はさておき、ClaudeのOCRが実際のユースケースにどのように適用されるかを見てみましょう。プロンプトの設計次第で、ワークフローに直接適用できる実際のビジネスシナリオをいくつか取り上げました。
例1:スキャンした請求書から財務表を抽出する
品目名、数量、単価の3つの列がある、ぼやけたベンダーの請求書のスキャン画像をアップロードしたと仮定します。従来のOCRエンジンでは、列が重なり合っている場合、文字が乱れて表示される可能性のある生のテキストが返されます。一方、Claudeは、適切にプロンプトを設定すれば、次のような出力を返します:
「この請求書には、コンサルティングサービス(40時間×150.00ドル=6,000.00ドル)、プロジェクト管理(20時間×175.00ドル=3,500.00ドル)、技術文書作成(15時間×125.00ドル=1,875.00ドル)の3つの明細が記載されています。小計:$11,375.00。8.5%の税額:$966.88。合計金額:$12,341.88。」
数値が抽出され、視覚的なレイアウトに基づいて計算が検証され、出力はすでに構造化されています。

例2:手書きの会議メモからフォーマットされた要約へ
あるコンサルタントが、クライアントのワークショップで作成された12ページの手書き会議メモを撮影しました。筆跡は統一されておらず、印刷体と筆記体が混在し、余白には矢印やアスタリスクがびっしりと書き込まれています。彼らは画像をClaudeにアップロードし、次のようなプロンプトを指定しました:「これを文字起こしし、『決定事項』『未解決の質問』『アクションアイテム』の3つに整理してください。」
Claudeは、整理された見やすい要約を返します。印刷された部分は正確に読み取り、筆記体の部分も高い精度で推測し、矢印やアスタリスクを単なるノイズではなく構造的なシグナルとして適切に解釈します。出力結果は、プロジェクト管理ツールにそのまま貼り付けることができます。
例3:開発者向けAPI駆動型ドキュメントパイプライン
ドキュメント処理ツールを構築している開発者が、Claude Codeを使用して手書きメモのOCR処理を大規模に自動化しています。このパイプラインは、各PDFページを150 DPIのPNGとしてレンダリングし、各画像をBase64エンコードした後、「手書きのテキストをすべて、書かれた通りに正確に転写してください」というプロンプトと共にClaudeのVision APIに渡し、結果をページごとに自動的にWord文書にまとめます。このワークフローにより、数時間かかっていた手作業での再入力作業が、1ページあたり数秒の処理で済むようになります。
OCRの問題点と、Claudeがそれらをどのように解決するか?
どのOCRツールにも弱点があります。従来のツールは、標準化された形式の文書では優れた性能を発揮します。しかし、条件がわずかに変化するだけで品質が低下してしまいます。以下に、実務で遭遇する問題と、Claudeがそれらをどのように解決するかを示します。
問題1:低品質なスキャン画像と画像ノイズ
きれいな文書データセットで学習された従来のOCRツールは、色あせたコピー、歪んだスキャン、コーヒーのシミがついたページ、または照明の悪い環境で撮影された画像では、著しく失敗します。文字認識がピクセルレベルで破綻した場合、代替手段はありません。
Claudeのアプローチ: Claudeは個々の文字だけでなく文脈を考慮して推論を行うため、曖昧さに耐えることができます。数字の一部が隠れている場合、Claudeは周囲の財務的な文脈を利用して、最も可能性の高い値を推測します。単に推測するだけではありません。真に不確実な場合は、その曖昧さをフラグ付けします。これ自体が有用な出力となります。
実用的な対処法: 低品質なスキャン画像で最良の結果を得るには、PDF全体を送信するのではなく、300 DPI以上のページ単位の画像をアップロードしてください。構造化された出力(JSONまたはCSV)をリクエストすることで、Claudeは「確信できる部分」と「不確実な部分」を明確に区別するよう強制されます。
問題2:複雑な複数列レイアウトと表
複数列の文書、新聞、学術論文、法廷書類、年次報告書は、ラスター順で左から右に読み取ると列が視覚的に重なり合うため、常にOCRエンジンを悩ませてきました。セルが結合されたり、ヘッダーがまたがったり、不規則な間隔が設けられた表は、さらに厄介です。
Claudeのアプローチ: Claudeはレイアウトを構造的に解析します。間隔のパターンから列の境界を検出し、表の境界線を意味的な区切りとして解釈し、結合されたセルも適切に処理します。複数行・複数列構造を持つ四半期財務報告書でのテストにおいて、Claudeは表の配置を維持し、正確な数値抽出を実現しました。これは、会計ソフトウェアに直接取り込んでも信頼できるような出力です。
問題3:幻覚テキスト
これはAI搭載OCRにおける最も危険な失敗モードの一つです。モデルが、画像には存在しないにもかかわらず、もっともらしいテキストを生成してしまうのです。医療記録、法的契約書、財務諸表といった重要な文書において、幻覚による条項や金額の生成は、現実世界で深刻な結果を招く可能性があります。
Claudeの解決策:最先端モデルの中でも、ClaudeはOCRタスクにおいて最も低い幻覚発生率の一つを示しており、CC-OCRベンチマークでの測定値は0.09%で、GPT-4oの0.15%を下回っています。Claudeは、空白をでっち上げた内容で埋めるのではなく、不確実性を認めるように設計されています。プロンプトエンジニアリングがこの点を強化します。「特定の箇所が明確に読めない場合は、推測するのではなく空白として記録してください」といった指示を含めることで、Claudeの「グレースフル・デグラデーション(段階的な機能低下)」動作が有効になります。
問題4:異なる文字体系が混在する多言語文書
例えば、見出しが英語で本文が日本語、あるいはアラビア語の注釈とフランス語の要約が混在するような文書は、ほとんどの単一言語向けOCR設定では処理できません。多言語に対応するツールであっても、言語を事前に指定する必要があることが多く、文書が真に混在している場合には機能しません。
Claudeのアプローチ: Claudeは設定なしで多言語文書を処理します。言語パックを選択する必要はありません。そこに書かれているものをそのまま読み取ります。ThaiOCRベンチマークにおいて、Claudeは94.2%の精度を達成し、テストされた最先端モデルの中でトップクラスの性能を示しています。この機能は、漢字が多用された日本語文書、アラビア語の右から左へのテキスト、ウルドゥー語、キリル文字にも適用されます。
課題5:単なる抽出ではなく解釈を必要とする文書
従来のOCRはテキストを提供します。しかし通常必要なのは意味です。スキャンされた研究論文は、単に文字が抽出されただけの「文字の壁」では役に立ちません。論文が何を論じているのか、図表が何を示しているのか、そして結論が方法論とどのように関連しているのかを知る必要があります。
Claudeの解決策: Claudeは単なる抽出にとどまらず、解釈まで行います。「図2は論文の中心的な主張をどのように裏付けているか?」というプロンプトを与えると、図を分析し、方法論のセクションと結びつけ、単に図の内容を記述するだけでなく、実質的な回答を生成します。これが、従来のどのOCRツールとも最も大きく異なる点です。
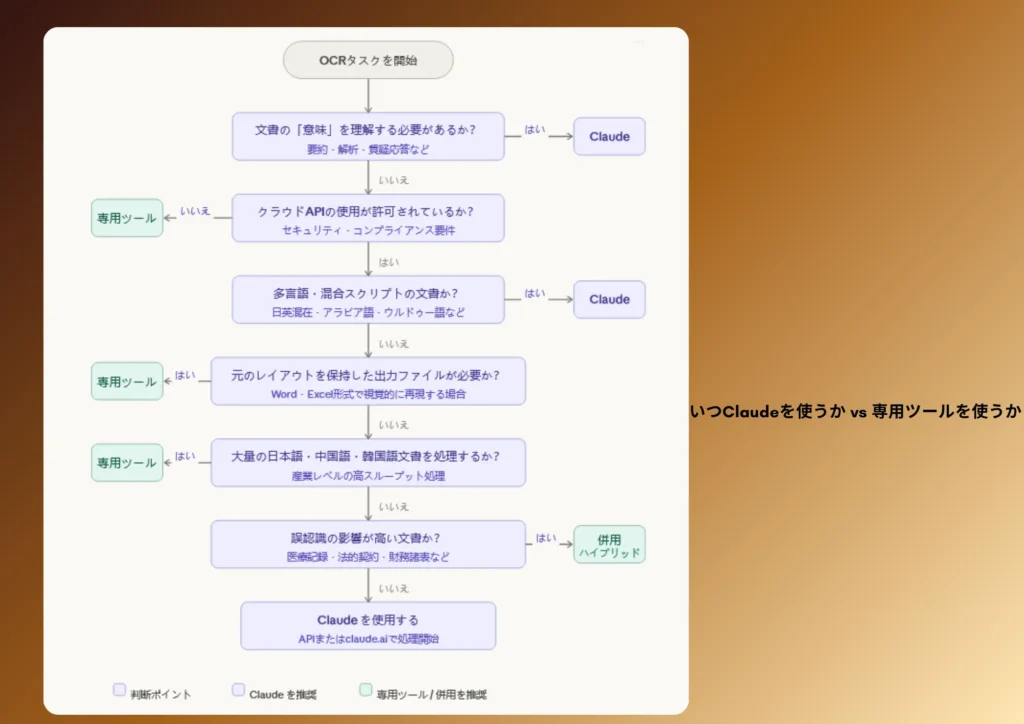
OCRにClaudeを使うべき場合と専用ツールを使うべき場合
以下の場合は、Claudeが適切な選択です:
- 単にテキストを抽出するだけでなく、文書の内容を理解する必要がある場合
- 文書が多言語、混合文字、または非標準的な書式である場合
- 言語パックやレイアウトテンプレートの管理をせずに、API駆動型のドキュメントインテリジェンスワークフローを構築したい場合
- 抽出されたコンテンツに基づいて、分析、要約、または質問応答を行うユースケースの場合
- 文字レベルの精度向上よりも、誤情報の抑制が重要である場合
- ABBYY FineReaderのような専用ツールが適しているのは、次のような場合です:
- 第三者機関による検証を経た、認証済みで法的に有効な精度数値が必要な場合
- 出力物が、視覚的に原本を忠実に再現した書式付き文書でなければならない場合
- 企業規模で日本語、中国語、または韓国語のテキストのみを処理しており、専用エンジンが必要な場合
- クラウドAPIの呼び出しが禁止されている厳格な環境下で作業している場合
ClaudeのOCRを使用する際のベストプラクティス
Claudeが優れたOCR機能を備えていることはすでに詳述しました。しかし、課題となるのは入力の品質とユーザーのプロンプトの設計にあります。以下は、Claudeを使用する際のベストプラクティスであり、これらを実践することで精度が向上し、誤認識が減少し、ワークフローにスムーズに統合できるようになります。
1. 300 DPI以上でスキャンする。 Claudeの視覚推論は、入力画像の品質によって制約を受けます。ピクセルが鮮明であればあるほど、曖昧な文字が減り、より確信度の高い解釈が得られます。
2. 複雑な文書はページごとにアップロードする。 複数のセクションからなるPDF全体を送信するのではなく、個々のページ画像に分割することで、レイアウトが複雑または変動する文書において精度が向上することがよくあります。
3. 構造化された出力を明示的に要求する。 結果をJSON、Markdownテーブル、またはCSVとして返すようClaudeに指示することで、構造化された推論が強制され、下流への統合が容易になります。
4. 段階的な精度低下への対応指示を使用する。「どのセクションでも不明瞭または部分的に判読できない場合は、推測するのではなく、その空白を明示的に記載してください」といった文言を含めます。これにより、誤った推論が抑制され、パイプラインの信頼性が保たれます。
5. 本番環境では、Claudeと前処理を組み合わせる。本番レベルのドキュメントパイプラインでは、専用のOCRツールで画像を前処理してテキストを抽出し、抽出したテキストをClaudeに渡して分析させます。このハイブリッドなアプローチにより、専門的なOCRの精度とClaudeの知能の両方を手に入れることができます。
結論
ClaudeのOCR機能は、ドキュメントインテリジェンスの定義におけるパラダイムシフトを表しています。従来のツールが「このテキストには何が書かれているか?」と問うのに対し、Claudeは「このドキュメントは何を意味しているか?」と問います。現実世界のユースケースの大部分において、実際に重要なのは後者の問いです。
Claudeは、生の処理能力、認定された精度、または書式付きドキュメントの出力が優先される場面において、専用のOCRインフラに取って代わるものではありません。しかし、単にドキュメントをデジタル化するだけでなく、大規模にドキュメントを理解する必要があるナレッジワーカー、開発者、研究者、そして企業にとっては、
Claudeは2026年時点で利用可能な最も高性能かつ費用対効果の高いツールです。
ドキュメントインテリジェンスの未来はOCRではありません。それは「理解」です。Claudeはすでにその段階に到達しています。
よくある質問
スキャンされたPDFとネイティブデジタルPDFでは、Claudeの処理方法は異なりますか?
スキャンされたものではなく、ソフトウェアから直接生成されたネイティブデジタルPDFには、テキストレイヤーが埋め込まれており、Claudeはこれをほぼ完璧な精度で読み取ることができます。スキャンされたPDFは画像ファイルとして扱われ、Claudeはビジョンベースの推論を用いてコンテンツを抽出・解釈します。スキャンされたPDFの場合、アップロード前にファイルを300 DPI以上の個々のページ画像に分割しておくと、PDF全体を一括で送信するよりも一貫して良い結果が得られます。
Claudeは、自動化されたドキュメントワークフローのためのAPI経由のOCRをサポートしていますか?
はい。Claudeのビジョン機能はAnthropic APIを通じて完全に利用可能であり、自動化されたドキュメント処理パイプラインを簡単に構築できます。開発者は、ページ画像をBase64エンコードし、構造化された抽出プロンプトと共にAPIに直接渡すことができます。その後、出力結果をデータベース、スプレッドシート、または下流のアプリケーションに転送できます。Files APIは最大500MBのドキュメントに対応しており、Claude Sonnet 4の100万トークンのコンテキストウィンドウにより、手動での分割処理を行うことなく、複数ページのドキュメントパッケージ全体を単一のリクエストで処理することが可能です。


