

2026年のAI業界は、かつてないほど接近し、厳しく、熾烈を極めており、各ツールには明確な違いが見られます。ライター、開発者、アナリストたちは、どのAIツールが他より優れているかを確かめるため、あらゆるツールを徹底的に検証しています。このガイドでは、ClaudeとChatGPTの決定的な比較を行います。機能、モデル、ベンチマークデータ、そして最適な活用事例など、あらゆる側面を詳細に分析していきます。
モデルを支える企業
ベンチマークの詳細に入る前に、まず哲学について触れておきたい。なぜなら、それが他のすべてを左右するからだ。
- Anthropicは、AI業界が安全性を十分に重視していないと考えたDario Amodei氏やDaniela Amodei氏ら、元OpenAIの従業員によって2021年に設立されました。その信念がClaudeのあらゆる設計上の決定を形作っています。つまり、誠実で適切に調整された応答を優先し、分からないことは素直に認め、そして「Constitutional AI(憲法型AI)」という安全装置をゼロから構築しているのです。
- 2015年に設立されたOpenAIは、ChatGPTを世界で最も認知されたAIブランドへと育て上げました。同社の哲学は「広範性とアクセシビリティ」に重点を置いており、テキストから画像、音声、動画に至るまで、AIのあらゆる機能を単一の製品でユーザーに提供しています。
Claude vs ChatGPT:主な違い
ClaudeもChatGPTも、それぞれ独自の能力を持つ高性能な言語モデルです。
- ChatGPTはオールインワンツールです。ユーザーは画像の作成、カスタムチャットボットの構築、ショッピングのリサーチ、AIエージェントを通じたタスクの遂行などが可能です。AI機能の全範囲を探求したいユーザーに最適です。
- Claudeは「コーダーの王様」として知られています。コードベース全体を開発したい開発者や、高度なクリエイティブ作業を行いたいクリエイターなら誰でも利用できます。
では、なぜClaudeが開発者、ライター、アナリストにとって最良の選択肢なのでしょうか?その答えは、すでにここにあると思います。
文章のスタイルは自然で、分析的なアプローチは思慮深く、エージェントコーディング機能は強力であり、ユーザーにとって強力なAIアシスタントとなっています。
モデルの比較
AnthropicとOpenAIはともに、特定のユースケース向けに設計された最先端のフラッグシップモデルを提供しています。
2026年3月、ChatGPTは最も高性能なモデルを導入し、最新のものはGPT-5.4 Thinkingです。ユーザーは複雑な質問に対してこれを利用でき、一方、GPT-5.3 Instantは日常的なチャット向けです。ChatGPT Plusユーザーは、依然として「最新」モデルと、GPT-5、GPT-5.2、推論モデルo3などの従来のモデルの中から選択するオプションを持っています。
Claudeは2026年4月に最新のOpus 4.6をリリースしました。これは高度な推論タスク、コーディング、およびエージェント型ワークフローに優れています。日常的なタスクにはSonnet 4.6が、より迅速な回答にはHaiku 4.5が提供されており、その他にもOpus 4.5、Opus 3、Sonnet 4.5などのモデルがあります。
「Claude対ChatGPT」は単なる単一モデルの対決ではなく、2つの製品エコシステム全体の比較です。各社の2026年のラインナップは以下の通りです。
Claude2026年モデル・ファミリー(Anthropic)
| モデル | 最適な用途 | API 価格設定(入力 / 出力 per 1M トークン) | コンテキストウィンドウ |
| Claude Opus 4.6 | 複雑な推論、研究、最先端のタスク | $5 / $25 | 1M トークン(ベータ版) |
| Claude Sonnet 4.6 | 日常使い — 最適な価格/パフォーマンスバランス | $3 / $15 | 200K トークン |
| Claude Haiku 4.5 | 高トラフィック、遅延に敏感なワークロード | $1 / $5 | 200K トークン |
消費者プラン: 無料(制限あり)、Claude Proは$20/月、Claude Maxは$100+/月
ChatGPTの2026年モデルファミリー(OpenAI)
| モデル | 最適な用途 | API 価格設定(入力 / 出力 per 1M トークン) | コンテキストウィンドウ |
| GPT-5.4 | 最先端の推論、エージェントタスク | $2.50 / $15 | 1M トークン |
| GPT-5.4 Mini | 予算に優しい一般的な使用 | $0.25 / $2.00 | 128K トークン |
| GPT-4o | 従来型マルチモーダルタスク、広範な採用 | $2.50 / $10 | 128K トークン |
Claudeの3段階のラインナップ(Haiku、Sonnet、Opus)は、開発者に明確なコスト最適化の道筋を提供します。Opus 4.6の100万トークンというコンテキストウィンドウは、企業の文書処理、法的レビュー、コードベース分析、長文リサーチにおいて、画期的な変化をもたらします。ChatGPTのGPT-5.4 Miniは、入力100万トークンあたり0.25ドルという市場最安値で最先端に近い性能を持つモデルであり、大規模な単純な分類タスクにおいては他を圧倒しています。
コンテキストウィンドウ
コンテキストウィンドウは、AIが1回の会話で処理できる情報量を決定します。
| プラットフォーム | 標準コンテキスト | 拡張コンテキスト |
| Claude (Sonnet 4.6) | 200,000 トークン | なし |
| Claude (Opus 4.6) | 200,000 トークン | 1M トークン(ベータ版) |
| ChatGPT (GPT-5.4) | 128,000 トークン | 1M トークン(思考) |
20万トークン ≈ 15万語 ≈ 長編小説2冊分。 Claudeの標準的なコンテキストウィンドウなら、コードベース全体や法的契約書、あるいは四半期分の財務報告書を貼り付け、セクション間の整合性を損なうことなく、分割することなく、そのすべてについて一度に質問することができます。
企業ユーザーにとって、これはしばしば決定的な要因となります。Claude Enterpriseの50万トークンという標準コンテキストウィンドウは、ChatGPT Enterpriseの約25万トークンを遥かに凌駕しています。大規模な文書を処理するチームにとって、その優位性は明白です。
ベンチマーク対決
AnthropicとOpenAIは、独自のスキャフォールドを使用してベンチマークスコアを公開しています。スキャフォールドの違いによって、スコアは5~10パーセントポイント変動する可能性があります。これらは正確な測定値ではなく、方向性を示す指標として捉えてください。
コーディング:SWE-bench Verified(業界標準)
実世界のソフトウェアエンジニアリングにおけるゴールドスタンダードです。本番環境のリポジトリから取得した実際のGitHubイシューを用いてモデルをテストします。
| モデル | SWE-bench スコア | 機能的コーディング精度 |
| Claude Opus 4.6 | 80.8% | ~95% |
| GPT-5.4 | ~80.0% | ~85% |
| Claude Sonnet 4.6 | 79.6% | ~92% |
Claudeは2025年の大半においてGPTモデルに後れを取っていたものの、2026年初頭以降、SWEベンチマークで一貫して首位を維持している。機能コーディングの精度における10ポイントの差は、実務上大きな意味を持つ。つまり、本番環境でのタスクにおいて、再試行の回数が減り、デバッグにかかるオーバーヘッドも軽減されるということだ。
推論と数学
| ベンチマーク | Claude Opus 4.6 | GPT-5.4 | 勝者 |
| AIME (数学オリンピアード) | 98 | 99 | GPT-5.4 |
| GPQA ダイアモンド (博士レベルの科学) | 高い | 高い | 概ね同じ |
| チャットボットアリーナ コーディング Elo | #1 (1561) | — | Claude |
| コンピュータ使用 (OSWorld) | 72.5% | 75% | GPT-5.4 |
GPT-5.4は純粋な数学的推論においてわずかに優位です。一方、Claudeは実世界のソフトウェアエンジニアリングや長文の分析において優れています。
ChatGPT vs Claude:実用的なユースケースの比較
ここでは、異なるシナリオにおいて同じ実世界のプロンプトを使用し、ChatGPTとClaudeをテストします。
各ユースケースを両モデルに全く同じ形で提示し、回答の推論、トーン、深み、構造の違いを観察します。この並行比較アプローチにより、各システムが実用的でタスクベースの条件下でどのように機能するかが明確になります。
ユースケース 1:創作・ストーリーテリング
ChatGPTとClaudeの両方に、短編小説の冒頭部分を書くようプロンプトを与えました。それぞれの応答は以下の通りです。
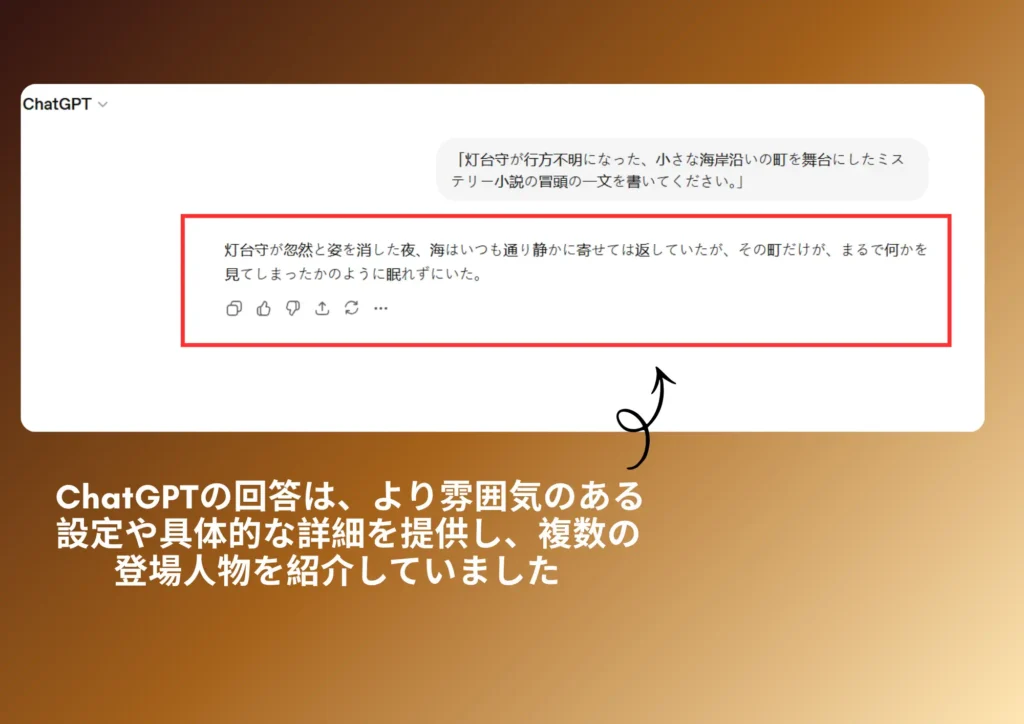
プロンプト: 「灯台守が失踪した、小さな海岸沿いの町を舞台にしたミステリー小説の冒頭段落を書いてください。」
ChatGPTの応答
Claudeの返答
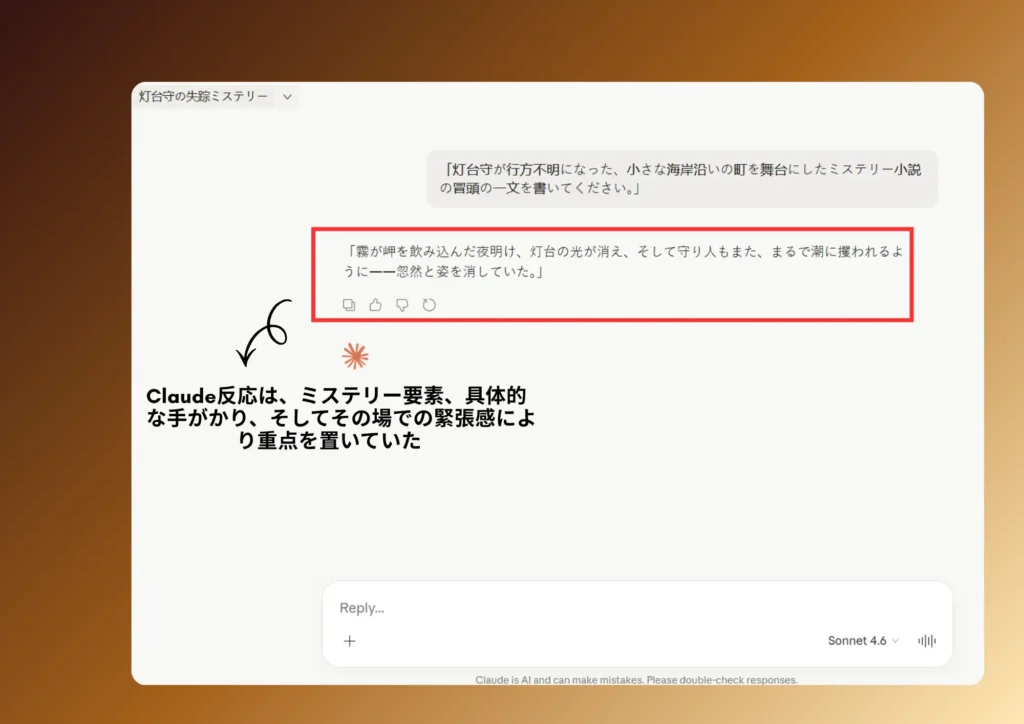
どちらの冒頭も「謎の失踪」を描こうとしているが、焦点、構成、トーン、そして物語の技法において違いが見られる。
ChatGPT版は、より雰囲気があり、観察的な視点に立っている。夜、海、町全体に漂う不安といった、より広範な情景を描き出している。失踪は間接的に暗示されており(「まるで何かを目撃したかのように」)、それによって曖昧さが生まれ、読者に謎を推測させる余地を残している。そのトーンはゆっくりと盛り上がり、内省的であり、出来事の展開よりも雰囲気を優先しています。
Claude版は、より出来事主導型で断定的なものです。特定の転換点(「夜明けに」)でその瞬間を定着させ、明確な因果関係(霧 → 灯台の明かりが消える → 守灯人が消える)を導入し、失踪をより直接的に述べています。これにより、より構造化され、映画的な印象を与え、物語のテンポもよりシャープになっています。
要約すると:
- ChatGPT: 雰囲気重視、間接的、心理的緊張、開放的な含意
- Claude: 構造的、時間軸が明確、より明示的な出来事の展開、映画的な明快さ
ユースケース2:テクニカルライティングとコード
ChatGPTとClaudeの両方にプロンプトを与えました。以下がそれぞれの回答です。
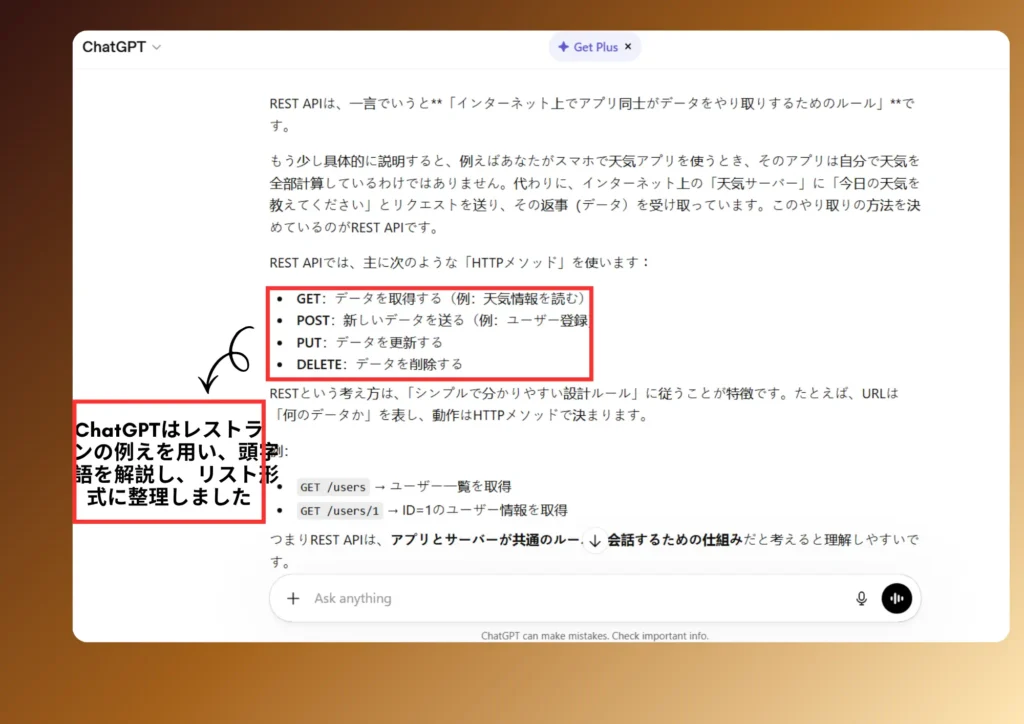
ChatGPTの回答
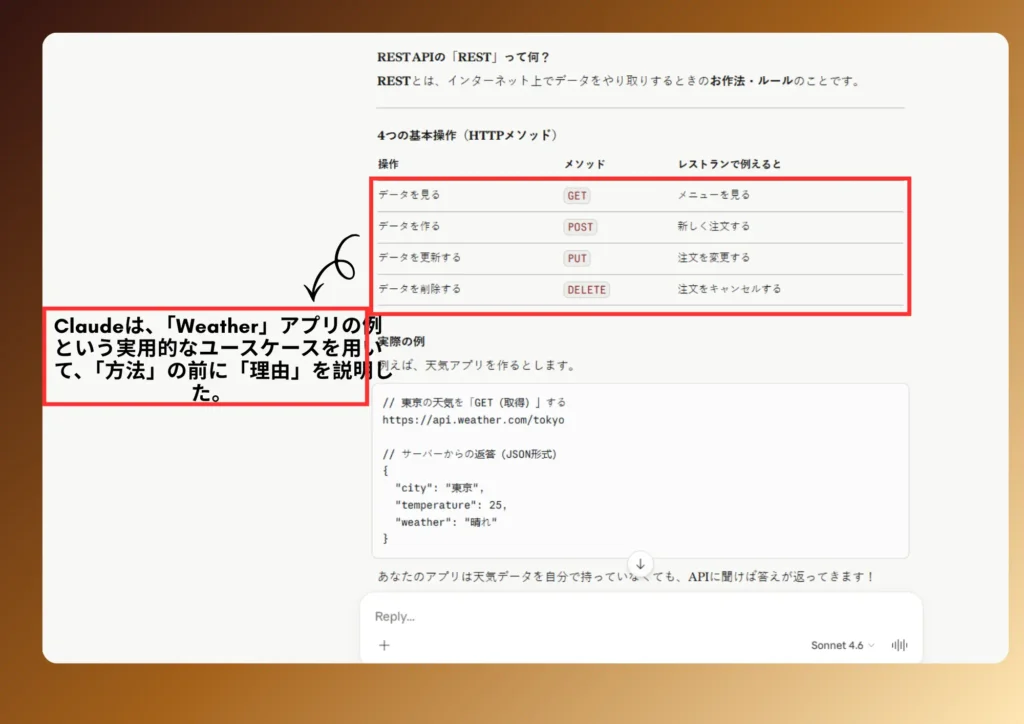
Claudeの返答
主な違い:
- ChatGPT:レストランの例え、頭字語の解説、構造化されたリスト形式
- Claude:天気アプリの例、実用的なユースケース、「方法」の前に「理由」を説明
ユースケース 3:コードのデバッグ
Python コードのエラーを修正するために、ChatGPT と Claude の両方に指示を出しました。
プロンプト: 「この Python コードが動作しません。修正して、エラーの原因を説明していただけますか?
ChatGPTの回答
問題は最後の行にあります。calculate_average()を引数なしで呼び出していますが、この関数はnumbersパラメータを期待しています。
何が間違っていたか: パラメータ(この場合はnumbers)を持つ関数を定義する場合、その関数を呼び出す際にはその引数を渡す必要があります。scoresリストを作成しましたが、それを関数に渡すのを忘れていました。

Claudeの回答
関数にscoresリストを渡すのを忘れていました!修正方法は以下の通りです:
失敗した理由: 関数calculate_average(numbers)はリストを受け取ることを想定していますが、calculate_average()で呼び出した際、処理に必要な引数を何も渡していませんでした。そのため、Pythonは「1つの必須の位置指定引数が不足しています」というエラーを返しました。

ChatGPTの強み
- 構造化された包括的な回答
- 正式なドキュメントや技術文書
- 詳細なステップバイステップガイド
- 学術的または専門的なトーン
- データに基づいた説明
Claudeの強み
- 会話的で分かりやすい説明
- 実践的で行動指向のアドバイス
- 複雑な事柄の微妙なニュアンスへの対応
- 直接的な問題解決
- 自然な対話とストーリーテリング
ChatGPTの機能
ChatGPTは、簡単な回答から詳細な調査、コンテンツ作成に至るまで、あらゆる作業をサポートするように設計された強力な機能群を提供します。これには、会話履歴の保持、ファイルや画像の分析、コード生成といった機能に加え、包括的で出典を明記した洞察を得るための詳細な調査といった高度なツールが含まれます。統合機能、カスタマイズオプション、マルチモーダル対応により、ChatGPTは幅広いタスクにおいて、文脈を認識した効率的なワークフローを実現します。
最近のファイル
2026年3月下旬、OpenAIはChatGPTに「ファイルライブラリ」機能を導入しました。ユーザーは、ChatGPTとのやり取り中にファイル、ドキュメント、または画像をアップロードすると、異なる会話間でそれらを直接再利用できるようになりました。これにより、特定のチャットスレッドへのアクセス制限が解消されます。
サイドバーにある「ライブラリ」タブからアクセスできます。
この機能は、ChatGPT Plus、Pro、およびBusinessユーザー向けに全世界で利用可能です。
ディープリサーチ
ChatGPTのディープリサーチは、単純な回答にとどまらず、詳細かつ体系的なレポートを作成することで、複雑で多段階にわたるクエリに対応するように設計された高度な機能です。この機能は、調査プロセスを計画し、複数の情報源(ウェブ、アップロードされたファイル、接続されたデータベースなど)から情報を収集し、検証用の引用情報を付加した一貫性のある出力として統合することで機能します。通常のチャット応答とは異なり、ディープリサーチでは、ユーザーが調査計画を確認・調整したり、進捗状況をリアルタイムで追跡したり、証拠に基づいた包括的な知見を生成したりすることができるため、学術研究、戦略的分析、および深い学習において特に有用です。
一例として、私たちはディープリサーチを使用して、さまざまな国の医療提供モデルのアクセシビリティ、成果、およびコストを比較しました。患者にとって最良の成果をもたらすシステムと、問題を抱えているシステムを特定することを目的としていました。
Codex
Codexは、AIを搭載したコーディングエージェントであり、ユーザーは自然言語による指示を使ってソフトウェアの記述、デバッグ、管理を行うことができます。コードの生成、エラーの修正、複雑なロジックの解説に加え、テストやドキュメント作成などのタスクを支援することで、開発をより迅速かつ効率的にします。仮想のソフトウェアエンジニアのように振る舞うCodexは、初心者からプロフェッショナルまで、ワークフローを合理化し、手作業によるコーディングよりも問題解決に注力できるよう支援します。
Claudeの機能
Claudeは、生産性を高め、複雑なタスクを効率化するために設計された、幅広い高度な機能を提供します。長文の文脈理解をサポートしており、ユーザーは膨大なドキュメントを分析し、高品質なコンテンツを生成し、長期にわたって一貫性のある会話を維持することができます。さらに、プロジェクト、ファイルアップロード、ツール連携などの機能により、より整理された、文脈を意識した、効率的なワークフローを実現します。
アーティファクト
アーティファクトを使用すると、チャットとは別の専用ワークスペース内で、アイデアをドキュメント、コード、アプリ、ビジュアルツールなどの構造化された再利用可能な成果物に変換できます。これらは通常、Markdownドキュメント、Reactコンポーネント、図表、さらには完全なシングルページWebサイトなど、内容が充実しており、独立した単位として成立し、反復開発を想定して設計された場合に作成されます。サイドバーからアーティファクトにアクセスして管理したり、Claudeにプロンプトを送ってリアルタイムで編集したり、バージョンを切り替えたり、会話の外でエクスポートや再利用を行ったりできます。また、アーティファクトは、AI機能の埋め込み、Model Context Protocol(MCP)を通じた外部統合の実装、ステートフルアプリケーション向けの永続データの保存といった高度な機能もサポートしています。インタラクティブなツールの構築、長文コンテンツの精緻化、あるいは複雑なプロジェクトでの共同作業など、どのような場面においても、アーティファクトは作業を効率的に作成、修正、拡張するための柔軟な環境を提供します。
以下では、アーティファクト機能を使用してインタラクティブなドラムマシンを作成し、斬新なビートを作ってみました。
プロジェクト
プロジェクトとは、会話、ファイル、コンテキストを1つの集中した環境に整理するための専用ワークスペースです。各プロジェクトには独自のチャット履歴とナレッジベースがあり、ドキュメント、コード、メモなどをアップロードすることで、Claudeがそれらを参照し、より関連性が高く文脈に沿った応答を提供できるようになります。
また、トーンや役割などの具体的な指示を設定することで、そのプロジェクト内でのClaudeの振る舞いを調整することも可能です。大規模なデータセットを扱うためのRAG(Retrieval Augmented Generation)や、チームでの共有を可能にするコラボレーション機能(有料プラン)といった高度な機能を備えたプロジェクトは、複雑なタスクや継続的な研究、チームベースのワークフローを、構造化された効率的な方法で管理するのに最適です。
それでは、両AIツールのどの機能が他方よりも優れているかを比較してみましょう。
Claudeが優れている点
- コーディングとソフトウェアエンジニアリング。 Claudeは、最も人気のある2つのAIコーディングエディタ(CursorとWindsurf)を支えています。Claude Proに含まれるエージェント型コーディング用のターミナルCLIであるClaude Codeは、年間25億ドルの収益を生み出していると報じられています。開発者たちがこぞって移行しています。
- 長文の執筆と編集。 Claudeの「Styles」機能を使えば、状況に応じて独自の文章スタイル(社内メモ、SNS向けコピー、長文の編集記事など)を定義できます。共同編集アプローチを採用しているため、現在の段落だけでなく、文書全体の文脈を理解します。
- 調整された正直さ。 公開データが乏しい場合やタスクが曖昧な場合、Claudeは自信満々だが間違った回答をでっち上げるのではなく、その旨を率直に伝えます。これはプロフェッショナルな場面において極めて重要です。
- 設計段階からの安全性。 Anthropicの「Constitutional AI」アプローチにより、規制産業(法律、医療、金融)において、より保守的でありながら信頼性の高いモデルが生み出されます。
ChatGPTが優れている点
- 画像および動画生成。 DALL-E 3の統合とSoraによる動画生成は、ChatGPTのネイティブ機能です。Claudeにはこれに相当する機能がありません。
- 音声対話。 高度な音声モードにより、ChatGPTは真に会話的なリアルタイムの音声対話を可能にします。これに対し、Claudeの音声機能は限定的です。
- コンピュータ操作。 OSWorld(実際のデスクトップタスクの自動化)におけるGPT-5.4のスコアは75%であるのに対し、Claudeは72.5%です。ブラウザベースのエージェントに関しては、現時点ではChatGPTがわずかに優位です。
- プラグインおよび統合エコシステム。 ChatGPTのプラグインエコシステムは歴史が長く、規模も大きい。ClaudeにはMCP(Model Context Protocol)があり、多くの開発者がそのアーキテクチャを優れていると評価しているが、MCPツールの導入ベースは依然として小さい。
- エンタープライズ向け成熟度。 OpenAIはより長い期間、企業向けに販売を行ってきた。多くのフォーチュン500企業がすでにChatGPT Enterpriseの契約を結んでいる。
機能比較の概要
| 特徴 | Claude | ChatGPT |
| コーディング (SWE-bench) | ✔ 最優秀クラス | ✔ ほぼ最優秀 |
| ロングフォームライティング | ✔ 優れた文章 | ✔ 良い |
| コンテキストウィンドウ(標準) | 200K トークン | △ 128K トークン |
| 画像生成 | ✖ | ✔ 40 画像生成器 |
| ビデオ生成 | ✖ | ✔ Sora |
| 音声インタラクション | △ 制限あり | ✔ 高度な音声モード |
| コンピュータ使用 | ✔ 72.5% OSWorld | ✔ 75% OSWorld |
| API エコシステム | ✔ MCP(エレガント) | ✔ プラグイン(大規模) |
| 消費者価格 | $20/月 | $20/月 |
| 企業向けコンテキスト | ✔ 500K トークン | △ 約250K トークン |
料金
Claude ProとChatGPT Plusはどちらも月額20ドルです。この価格帯において、両者の違いは提供される機能にあります:
- Claude Proには、追加料金なしでClaude Code CLIが含まれており、利用制限付きでSonnet 4.6およびOpus 4.6を利用できます。
- ChatGPT Plusには、DALL-Eによる画像生成、ウェブブラウジング、および利用制限付きでGPT-5.4へのアクセスが含まれています。
主にテキストやコードの処理にAIを使用する場合:Claude Proの方がコストパフォーマンスに優れています。マルチモーダル機能(画像、音声、動画)が必要な場合:ChatGPT Plusの方がコストパフォーマンスに優れています。
APIの料金体系(開発者向けプラン)
| モデル | 入力(1Mトークンあたり) | 出力(1Mトークンあたり) |
| Claude Haiku 4.5 | $1.00 | $5.00 |
| Claude Sonnet 4.6 | $3.00 | $15.00 |
| Claude Opus 4.6 | $5.00 | $25.00 |
| GPT-5.4 Mini | $0.25 | $2.00 |
| GPT-5.4 | $2.50 | $15.00 |
大量の開発を行う開発者にとって、GPT-5.4 Miniは最先端技術に近い選択肢の中で最も安価なものです。品質が実際に重要となる精度重視のワークロード(本番環境のコード、法的分析、複雑な推論など)においては、トークン単価は高いものの、Claude Sonnet 4.6の方が「正解あたりのコスト」が低い場合が多くあります。
最適な用途
以下は、ClaudeまたはChatGPTを使用すべき状況の例です。
次のような場合はClaudeを選択してください:
- プロとしてコードを記述しており、利用可能な中で最も高性能なコーディングアシスタントを求めている場合
- 長文のドキュメント(契約書、研究資料、コードベース、議事録)を扱う場合
- 品質と文体が重要な長文コンテンツを作成する場合
- 正確で誠実な応答が不可欠な規制産業で働いている場合
- API経由でアプリケーションを構築する開発者であり、洗練されたMCP統合を求めている場合
次のような場合はChatGPTを選択してください:
- ワークフローの一環として画像や動画の生成が必要な場合
- リアルタイムの音声会話機能が必要な場合
- すでにMicrosoft 365エコシステムを利用している場合(Copilotとの統合)
- ワークフローの自動化のために大規模なプラグインエコシステムが必要な場合
- 「何でも少しはできる」汎用AIアシスタントを好む場合
以下の場合は両方を使用してください:
- 大規模なAPI駆動型製品を開発している場合(簡単なタスクは安価なモデルに、難しいタスクは最高のモデルに割り当てる)
- 公開や出荷前に、重要なコンテンツの出力を比較したい
- 特定のプラットフォームで定期的に利用制限に引っかかる
結論
両社が認めたがらないほど、モデルの品質は急速に接近しています。1年前に存在した「明らかに最高」と「明らかに2番手」の間の差は、程度の問題や専門性の違いに縮まりました。
Claudeは奥行きがあります。コーディング、長文執筆、微妙なニュアンスを含む分析、そして膨大なドキュメントの処理には、こちらの方が適しています。Anthropicは、広さよりも深さを重視するという明確な賭けに出ました。ChatGPTは、画像、音声、動画、プラグインといった機能を備え、企業での導入においても先行していることから、より優れた「万能ツール」と言えます。OpenAIは、ユーザーが最初に手に取るプラットフォームになることを目指して、明確な賭けに出ました。
2026年に取るべき最善の策は、一方を選んで他方を削除することではありません。それぞれの強みを理解し、実際のワークフローで1週間ほど両方を試用し、その結果に基づいて判断することです。
よくある質問
ChatGPTとClaudeは、同じプロンプトに対して大きく異なる回答をしますか?
はい、トーン、深み、推論のスタイルが異なる場合があります。ChatGPTは通常、より直接的で構造化された出力を提供するのに対し、Claudeは文脈が豊かで物語性のある応答を返すことがあります。
どちらのモデルがより正確で信頼性が高いですか?
どちらのモデルも非常に高性能ですが、正確さはユースケースによって異なります。使用するモデルに関わらず、プロンプトが明確かつ具体的である場合、一般的に最良の結果が得


